Gilthanis
[H]ard|DCer of the Year - 2014
- Joined
- Jan 29, 2006
- Messages
- 8,742
This post gets updated throughout the event. Always check back for updates!
https://www.seti-germany.de/boinc_pentathlon/
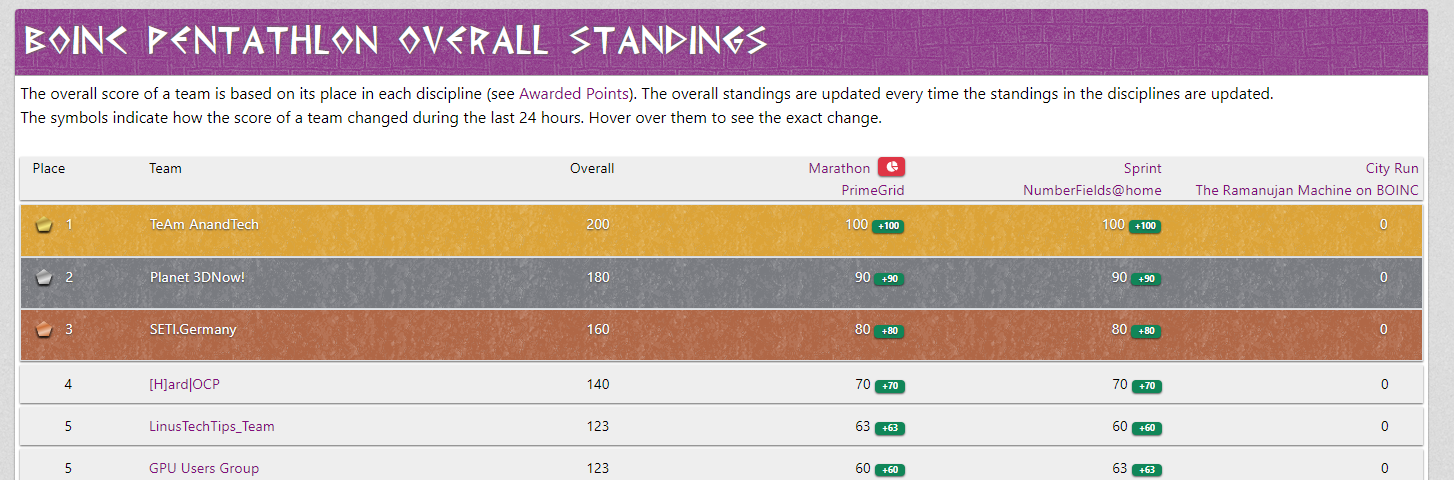
The BOINC Pentathlon starts on 05 May 2024, 00:00 UTC, and ends on 19 May 2024, 00:00 UTC. So, it will run for exactly 14 days. We finished in 5th place last year.
The BOINC Pentathlon consists of 5 disciplines:

Previous year's threads
2023 - https://hardforum.com/threads/seti-germanys-14th-annual-pentathlon-2023.2026968/
2022 - https://hardforum.com/threads/seti-germanys-13th-annual-pentathlon-2022.2018539/
2021 - https://hardforum.com/threads/seti-germanys-12th-annual-boinc-pentathlon-2021.2009895/
2020 - https://hardforum.com/threads/seti-germanys-11-annual-boinc-pentathlon-2020.1995136/
2019 - https://hardforum.com/threads/2019-boinc-pentathlon.1980089/#post-1044154864
2018 - https://hardforum.com/threads/9th-annual-boinc-pentathlon-hosted-by-seti-germany.1957969/
2017 - https://hardforum.com/threads/10th-...sted-by-seti-germany.1980020/#post-1044152665
2016 - https://hardforum.com/threads/7th-annual-boinc-pentathlon-2016.1896285/
2015 - https://hardforum.com/threads/boinc-pentathlon-2015.1858766/
https://www.seti-germany.de/boinc_pentathlon/
The BOINC Pentathlon starts on 05 May 2024, 00:00 UTC, and ends on 19 May 2024, 00:00 UTC. So, it will run for exactly 14 days. We finished in 5th place last year.
The BOINC Pentathlon consists of 5 disciplines:
- Marathon (14 days) - PrimeGrid (Cullen Prime Search LLR sub project ONLY!)
After making your account, make sure to join our team at this link - https://www.primegrid.com/team_display.php?teamid=1710
For those wanting a sit and forget contribution, this is the one to set up.
These work units are quorum of 1. So, no need for a wingman to confirm it. Just get them returned within the deadline. - Sprint (3 days) - Numberfields (CPU and GPU capable)
5/5 - 5/8, After joining the project make sure you join the team at this link - https://numberfields.asu.edu/NumberFields/team_display.php?teamid=19
These work units are quorum of 1. So, no need for wingmen. Just get them returned within the deadline and hopefully the validator doesn't take a dump before time is up. - City Run (5 days) - The Ramanujan Machine (CPU only)
5/7 - 5/12 - After making your account, make sure to join our team at this link - https://rnma.xyz/boinc/team_display.php?teamid=2
These work units are quorum of 2. Therefore you need a wingman to verify your work before getting credit. It is smartest to grab all you can complete all at the beginning in a large cache so that it increases the odds of getting validated before the end date.
Be careful pausing/suspending work. They will reset to the beginning and start over. - Steeplechase (7 days, with bonus credits on 2 one-day obstacles)
- Javelin Throw (5 x 1 day, only each team's third best daily score counts)
Previous year's threads
2023 - https://hardforum.com/threads/seti-germanys-14th-annual-pentathlon-2023.2026968/
2022 - https://hardforum.com/threads/seti-germanys-13th-annual-pentathlon-2022.2018539/
2021 - https://hardforum.com/threads/seti-germanys-12th-annual-boinc-pentathlon-2021.2009895/
2020 - https://hardforum.com/threads/seti-germanys-11-annual-boinc-pentathlon-2020.1995136/
2019 - https://hardforum.com/threads/2019-boinc-pentathlon.1980089/#post-1044154864
2018 - https://hardforum.com/threads/9th-annual-boinc-pentathlon-hosted-by-seti-germany.1957969/
2017 - https://hardforum.com/threads/10th-...sted-by-seti-germany.1980020/#post-1044152665
2016 - https://hardforum.com/threads/7th-annual-boinc-pentathlon-2016.1896285/
2015 - https://hardforum.com/threads/boinc-pentathlon-2015.1858766/
Attachments

Last edited:

") .
.